These commits are when the Protocol Buffers files have changed: (only the last 100 relevant commits are shown)
| Commit: | 43e4594 | |
|---|---|---|
| Author: | Xuanwo | |
fix: avoid persisting unrelated FTS stop words
| Commit: | 1c65d26 | |
|---|---|---|
| Author: | Xuanwo | |
feat: add code analyzer for FTS
| Commit: | 0ffaac8 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
docs: relocate data overlay conflict and index rules to canonical docs Move the DataOverlay conflict-resolution rules out of the transaction.proto comment into transaction.md as a DataOverlay operation + Compatibility section, matching the pattern used for every other operation. Consolidate the reader-side overlay handling in the index doc and make re-evaluation explicit. Mark the feature experimental, drop the open-questions section, and cross-link the three docs. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 4141eb5 | |
|---|---|---|
| Author: | Will Jones | |
feat(transaction): add opaque experimental-operation wire hook Add an ExperimentalUserOperation message + oneof arm (field 115) to the canonical transaction.proto. The action list is carried as an opaque `bytes` payload (a serialized experimental UserOperation) so the PMC-voted schema stays free of the unstable action structure. Builds that cannot interpret it reject the transaction; a real Operation variant is wired up in the next commit. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 4fd0d19 | |
|---|---|---|
| Author: | Will Jones | |
feat(transaction): add NewFragment placeholder + AddIndex action Extend the experimental action-transaction types for the first compound-commit slice. `AddFragments` now carries `NewFragment`s, each with an operation-local `local_id` placeholder so a later action can reference a fragment before its real id is assigned. Adds the `AddIndex` action, which registers an index segment and expresses coverage as the union of already-committed fragment ids and same-op placeholders. All behind the non-default `unstable-action-transactions` feature. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | f464a85 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
feat(transaction): experimental action-based transaction skeleton Skeleton for the Action-based Transactions milestone (discussion #5960), gated behind the non-default `unstable-action-transactions` Cargo feature so it is absent from released artifacts. Stacked on the general experimental-feature mechanism (#7646): rather than claiming a dedicated feature-flag bit, action-based transactions are the first consumer of FLAG_EXPERIMENTAL. A dataset declares the "action-transactions" experimental feature (registered in `known_experimental_features` under the Cargo feature), which sets the bit so libraries without it fail closed. - protos/transaction_experimental.proto: UserOperation / UserAction / Action (AddFragments only), compiled only under the feature. - lance_table::transaction: UserOperation/UserAction/Action/AddFragments Rust types with protobuf conversions and a roundtrip test; FEATURE_NAME constant. - Register "action-transactions" in the experimental-feature registry, with admission tests for both default (rejected) and feature-on (recognized). The wire format carries no compatibility guarantee until finalized by PMC vote, at which point it graduates to its own feature-flag bit. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 8d5feee | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | Xuanwo | |
perf(lance): honor unordered filtered reads
| Commit: | 1aca0a6 | |
|---|---|---|
| Author: | Xuanwo | |
feat: add sparse validity polarity
| Commit: | 6c1e0ae | |
|---|---|---|
| Author: | Will Jones | |
feat(format): general experimental-feature mechanism Proposes and implements a general mechanism for shipping experimental format features without burning a permanent feature-flag bit per experiment. Policy (design doc) and the proto/format change are together so they can be reviewed and voted on as one. Mechanism: - Reserve one persisted bit, FLAG_EXPERIMENTAL (1 << 6, reusing the old first FLAG_UNKNOWN bit), meaning "this dataset uses experimental feature(s)". It is the fail-closed anchor: pre-mechanism libraries reject the dataset on the bit alone. - Carry feature identities in free-form manifest string lists (experimental_reader_features / experimental_writer_features). New libraries admit a dataset iff they understand every declared name. - A compile-time registry (known_experimental_features) lists the experiments a build understands, gated by each experiment's Cargo feature; a default build understands none and so rejects any experimental dataset. This keeps experiments free-flowing (unbounded string namespace, mint/abandon at will) while the bitmap stays conservative (a bit is spent only at graduation). Design, graduation/lifecycle, alternatives, and prior art (Delta Lake table features) in rust/lance-table/design/experimental_feature_flags.md. can_read_dataset / can_write_dataset now take the declared experimental feature list alongside the flags (two internal callers updated). Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 3482df3 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
feat: add DataOverlay transaction operation Add the `DataOverlay` operation (and `DataOverlayGroup`) to attach overlay files to fragments without rewriting their base data. Mirrors the `DataReplacement` batch shape, appends to each fragment's `overlays` list, and documents permissive conflict semantics: concurrent overlays, appends, deletes, and column rewrites are compatible; row-rewrites, compaction, and overlay->base folds conflict. committed_version is left 0 by the writer and stamped at commit time. Proto only — Rust/Python bindings deferred. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | a4d4fa8 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
docs: specify data overlay files for the table format Add a specification for data overlay files: small files attached to a fragment that supply new values for a subset of (row offset, field) cells without rewriting the base data files, for cheap cell-level updates. - protos/table.proto: rework DataOverlayFile with a dense/sparse coverage oneof (shared_offset_bitmap vs new FieldCoverage), rename read_version to committed_version (effective, commit-stamped), and document rank-based addressing with no offset column. Document reader feature flag 64. - docs: add data_overlay_file.md (full spec, worked example, guidance stub) and link it from the table format overview. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 88a47e4 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
feat: add DataOverlay transaction operation Add the `DataOverlay` operation (and `DataOverlayGroup`) to attach overlay files to fragments without rewriting their base data. Mirrors the `DataReplacement` batch shape, appends to each fragment's `overlays` list, and documents permissive conflict semantics: concurrent overlays, appends, deletes, and column rewrites are compatible; row-rewrites, compaction, and overlay->base folds conflict. committed_version is left 0 by the writer and stamped at commit time. Proto only — Rust/Python bindings deferred. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | aab9f18 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
docs: specify data overlay files for the table format Add a specification for data overlay files: small files attached to a fragment that supply new values for a subset of (row offset, field) cells without rewriting the base data files, for cheap cell-level updates. - protos/table.proto: rework DataOverlayFile with a dense/sparse coverage oneof (shared_offset_bitmap vs new FieldCoverage), rename read_version to committed_version (effective, commit-stamped), and document rank-based addressing with no offset column. Document reader feature flag 64. - docs: add data_overlay_file.md (full spec, worked example, guidance stub) and link it from the table format overview. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 6d11ddf | |
|---|---|---|
| Author: | Yang Cen | |
Merge branch 'main' into yang/oss-1344-make-fts-index-block-size-configurable Reconciles #7600's tokens_only DocSet cache with this branch's quantized_scoring flag: the cached num_tokens-only DocSet is built with quantized scoring applied inside the OnceCell init, matching how ensure_loaded stamps the full DocSet.
| Commit: | 06447f1 | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | GitHub | |
feat: add RLE v2 run length widths (#7376) ## Summary Adds RLE v2 run-length widths so newly created datasets can write RLE pages with `u16` or `u32` run lengths instead of splitting every run at 255 values. The capability is recorded as a reader feature flag and is only enabled when a new dataset is created with `WriteParams::enable_rle_v2`; existing unflagged datasets reject attempts to turn it on mid-stream. Closes #7327. ## Benchmark Ran on `xuanwo-lance-lazy-metadata-bench` with a #6941-style sorted low-cardinality `asset_id` workload. | workload | Lance default | Lance RLE2 | reduction | |---|---:|---:|---:| | `150M rows / 5k assets / random5 value` | `167.36 MiB` | `164.57 MiB` | `1.67%` | | `150M rows / 5k assets / by-asset5 value` | `7.62 MiB` | `2.03 MiB` | `73.34%` | The first row keeps the random low-cardinality value column from the issue-like workload, which dominates total size. The second row isolates the long-run case RLE2 targets. ## Validation Validated with focused RLE2 tests and full Rust clippy before publishing.
| Commit: | 6489916 | |
|---|---|---|
| Author: | Xuanwo | |
feat: use semantic sparse structural sets
| Commit: | 96b172d | |
|---|---|---|
| Author: | Yang Cen | |
| Committer: | Yang Cen | |
feat(fts): impact skip data for posting lists Store per-block (freq, doc_len) impact frontiers alongside 256-doc posting blocks (varint-encoded: 2-3 bytes per pair) plus one level1 entry per 32 blocks, and drive block-max WAND pruning from them instead of build-time scores that go stale as index stats drift: - Bounds bake once per cached list into an Arc-shared slab (max doc weight per entry plus the list-wide max); per-query clones reuse it, so query time pays one multiply per bound instead of frontier rescans. - Entry doc_up_tos decode once at construction. - Lagging iterators park in the WAND tail under the data-driven global bound (query_weight x baked list max) instead of INFINITY. 128-doc-block indexes keep fixed-width u32 impact entries.
| Commit: | 9230361 | |
|---|---|---|
| Author: | Xuanwo | |
feat: add sparse structural encoding
| Commit: | 1ee1cce | |
|---|---|---|
| Author: | Xuanwo | |
refactor: gate RLE v2 on file version 2.3
| Commit: | 0ec1da3 | |
|---|---|---|
| Author: | Yang Cen | |
feat(fts): impact skip data for posting lists Store per-block (freq, doc_len) impact frontiers alongside 256-doc posting blocks (varint-encoded: 2-3 bytes per pair) plus one level1 entry per 32 blocks, and drive block-max WAND pruning from them instead of build-time scores that go stale as index stats drift: - Bounds bake once per cached list into an Arc-shared slab (max doc weight per entry plus the list-wide max); per-query clones reuse it, so query time pays one multiply per bound instead of frontier rescans. - Entry doc_up_tos decode once at construction. - Lagging iterators park in the WAND tail under the data-driven global bound (query_weight x baked list max) instead of INFINITY. 128-doc-block indexes keep fixed-width u32 impact entries.
| Commit: | 7af42dd | |
|---|---|---|
| Author: | Yang Cen | |
feat(index): add impact skip data for fts
| Commit: | 2603b4c | |
|---|---|---|
| Author: | Xuanwo | |
perf(lance): honor unordered filtered reads
| Commit: | 9b4ecd2 | |
|---|---|---|
| Author: | BubbleCal | |
Merge remote-tracking branch 'origin/main' into yang/oss-1344-make-fts-index-block-size-configurable
| Commit: | 8f7e027 | |
|---|---|---|
| Author: | BubbleCal | |
| Committer: | BubbleCal | |
feat(bitpacking): add owned bitpacking codecs
| Commit: | 4760024 | |
|---|---|---|
| Author: | Dan Rammer | |
| Committer: | GitHub | |
feat(mem-wal): add ShardWriter::abort + Sealed manifest fence for drop-table (#7361) ## What The mem-wal primitives sophon's drop-table two-phase commit needs: - **`ShardWriter::abort(&self)`** — shut down the background flush tasks (`task_executor.shutdown_all()`) *without* flushing, discarding buffered memtable state. Unlike `close(self)` it takes `&self` (so it's callable through the `Arc<ShardWriter>` callers hold) and does no object-store IO. The caller must quiesce writes first (documented). Idempotent. Acked data is **not** lost — it's durable in the WAL log and replays on the next claim, which is what makes the drop's prepare phase reversible. - **`ShardStatus { Active | Sealed }` on `ShardManifest`** — a durable, reversible lifecycle marker (proto + struct + serde). `claim_epoch` refuses a `Sealed` manifest with a **distinguishable** error instead of minting a new epoch, so a shard mid-drop can't be re-claimed — even by a caller that skips its own status check — and a reader can tell an in-doubt drop apart from an ordinary epoch fence. Set/cleared through the existing epoch-guarded `commit_update` CAS; carried across claims via `..base`, so only the genuinely-fresh constructions default it to `Active`. ## Why A WAL-enabled table's drop spans two durable resources — the owning pod's fresh-tier state and the catalog/object-store data — so sophon's teardown is a two-phase commit. Before the dataset directory is removed, the owning pod must: - `abort` the writer so its background flush task can't re-create `_mem_wal/` under the just-deleted directory (a graceful `close()` would flush it back), and - durably mark the shard `Sealed` so the drop is in-doubt across a pod crash or a Maglev rehome — which the in-memory fence flag cannot survive. The seal is reversible (rollback clears it back to `Active`), making the prepare phase abortable without data loss. Both build on existing machinery (`shutdown_all`, the manifest CAS) — thin exposure, not new infrastructure. > **Changed since first draft:** this PR previously also added `Session::invalidate_dataset`; it has been **dropped**. Base-table read freshness rides the recreate's new object-store `e_tag` (the QN→PE and lance metadata caches are `e_tag`-keyed and miss the stale entry), so cache invalidation isn't load-bearing — only `abort` and the `Sealed` marker remain. ## Tests - `test_abort_discards_without_flushing_and_is_idempotent` — `abort` leaves no new L0 generation (contrast with `close`), idempotent on a second call. - `test_claim_epoch_refuses_sealed_manifest` — a `Sealed` manifest is refused with the distinguishable error and left untouched (no epoch minted); rolling the status back to `Active` makes the shard claimable again (reversibility). 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 059ae90 | |
|---|---|---|
| Author: | BubbleCal | |
| Committer: | BubbleCal | |
feat(fts): add configurable posting block size
| Commit: | 11ea361 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | Daniel Rammer | |
refactor!: rename FMIndexIndexDetails to FMIndexDetails (#7397) I'm not sure if the original naming was intentional or not. However, it required a special case in `get_plugin_name_from_details_name` to rename `fmindex` to `fm` so I'm guessing it was accidental? We are trying to convert indexes to be "generic plugins" and this means we cannot have special cases lying around. An index's short-name is the name of the type URL minus the suffix `IndexDetails`. So if we want `fm` then it should be `FmIndexDetails` (which this PR implements). If we want `fmindex` then it should be `FmIndexIndexDetails` (which it had before). If we want both then we should invent some kind of formal alias mechanism where an index plugin can register potential aliases. However, I think it'd be simplest to avoid that. This change would be a breaking change to any existing FM indexes! That index type has not (AFAIK) been formally released yet so I think this is ok. However, if this misses the 8.0.0 release then we will probably need to find a different way (and possibly forever be locked into carrying around this special case). --------- Co-authored-by: Claude Sonnet 4.6 <noreply@anthropic.com>
| Commit: | 5328f64 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
refactor!: rename FMIndexIndexDetails to FMIndexDetails (#7397) I'm not sure if the original naming was intentional or not. However, it required a special case in `get_plugin_name_from_details_name` to rename `fmindex` to `fm` so I'm guessing it was accidental? We are trying to convert indexes to be "generic plugins" and this means we cannot have special cases lying around. An index's short-name is the name of the type URL minus the suffix `IndexDetails`. So if we want `fm` then it should be `FmIndexDetails` (which this PR implements). If we want `fmindex` then it should be `FmIndexIndexDetails` (which it had before). If we want both then we should invent some kind of formal alias mechanism where an index plugin can register potential aliases. However, I think it'd be simplest to avoid that. This change would be a breaking change to any existing FM indexes! That index type has not (AFAIK) been formally released yet so I think this is ok. However, if this misses the 8.0.0 release then we will probably need to find a different way (and possibly forever be locked into carrying around this special case). --------- Co-authored-by: Claude Sonnet 4.6 <noreply@anthropic.com>
| Commit: | fbd230a | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
docs: specify data overlay files for the table format Add a specification for data overlay files: small files attached to a fragment that supply new values for a subset of (row offset, field) cells without rewriting the base data files, for cheap cell-level updates. - protos/table.proto: rework DataOverlayFile with a dense/sparse coverage oneof (shared_offset_bitmap vs new FieldCoverage), rename read_version to committed_version (effective, commit-stamped), and document rank-based addressing with no offset column. Document reader feature flag 64. - docs: add data_overlay_file.md (full spec, worked example, guidance stub) and link it from the table format overview. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 6aaca5e | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | Will Jones | |
feat: add DataOverlay transaction operation Add the `DataOverlay` operation (and `DataOverlayGroup`) to attach overlay files to fragments without rewriting their base data. Mirrors the `DataReplacement` batch shape, appends to each fragment's `overlays` list, and documents permissive conflict semantics: concurrent overlays, appends, deletes, and column rewrites are compatible; row-rewrites, compaction, and overlay->base folds conflict. committed_version is left 0 by the writer and stamped at commit time. Proto only — Rust/Python bindings deferred. Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | 5d3e838 | |
|---|---|---|
| Author: | Xuanwo | |
feat: add RLE v2 run length widths
| Commit: | d076a7a | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
feat: stabilize cache codec with a versioned envelope (#7163) Implements #7160. Cache entries (FTS posting lists, scalar/vector index state) were serialized with an ad-hoc, unversioned format only safe to read in the same process that wrote it. This stabilizes the format so entries can live in a **node-agnostic, restart-surviving** cache backend. ## Wire format Each entry is an envelope followed by a body: ```text [magic "LCE1"][envelope_version: u8][type_id][type_version: u32] # envelope <body: optional protobuf header, then sections in a fixed, version-keyed order> ``` Body sections, each self-delimiting: ```text HEADER : [len: u32][protobuf bytes] ARROW_IPC : [pad to 64B][self-delimiting IPC stream] RAW_BLOB : [len: u64][bytes] ``` ## Why this shape - **The envelope is hand-framed, not protobuf.** It's the most stability-critical part: it must parse robustly against *any* bytes (including old, pre-stabilization blobs) and never change shape. The magic is chosen so no prior blob can collide with it. - **Decode returns `Hit`/`Miss`, never a hard error.** Wrong/absent magic, an unknown envelope version, a `type_id` mismatch, a future `type_version`, or a body decode failure all become `Miss` → recompute. Old, foreign, or corrupt bytes self-heal with **zero migration code**. - **Bodies use protobuf headers.** Field-number evolution lets us add fields without a format break; only changes protobuf can't express transparently (reordering sections, changing a raw-blob encoding) bump `type_version`, which the reader branches on. - **Arrow IPC sections are 64-byte aligned** so concatenated sections decode zero-copy instead of a realigning `memcpy` on every read — this guards the FTS WAND hot path. - **`RAW_BLOB` is reserved for payloads with their own portable, self-describing encoding** (roaring bitmaps, the shared position stream). A codec with no scalar metadata (e.g. bitmap) simply omits the header — sections are positional, so nothing is written for an absent header. ## Scope All cache codecs migrated: FTS posting lists (compressed/plain/positions + groups), scalar indices (BTree/Bitmap/Flat/LabelList/RowAddrTreeMap), and the five IVF quantizer partitions + IVF state. The cache protos live in `lance-index/protos-cache/cache.proto` (`package lance.index.cache`) — they describe *library serialization*, not the on-disk format spec. ## Tests Envelope round-trip and every miss path; per-codec round-trip + through-envelope zero-copy alignment (incl. RabitQ Matrix rotation, multi-batch SQ, nested bitmap in a label-list entry); additive proto-field compat; existing IVF build+search suites pass through the migrated path. Closes #7160. 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
| Commit: | e256207 | |
|---|---|---|
| Author: | Yang Cen | |
| Committer: | GitHub | |
feat(vector)!: add approx mode for RaBitQ search (#7179) ## Feature This PR adds a public `approx_mode` setting for vector search with `fast`, `normal`, and `accurate` values. The public API avoids exposing RaBitQ/HACC terminology while still allowing callers to choose the speed/accuracy tradeoff when the backing index supports it. ## Implementation - Adds `ApproxMode` to vector queries and threads it through Rust scanner, ANN proto serialization, Python query parsing, and FlatIndex distance calculator options. - Implements RaBitQ behavior for each mode: - `fast`: force 1-bit query-time scoring for RaBitQ. - `normal`: preserve the existing search path. - `accurate`: use a 16-bit LUT accumulation path for the binary RaBitQ estimator. - Extends query scratch with a wider accumulation buffer while keeping the existing `QueryScratchCapacity::new(...)` API compatible. - Adds Python API support via `approx_mode="fast" | "normal" | "accurate"` and rejects invalid values. ## Benchmark IVF_RQ on dbpedia, `num_bits=5`, no `refine_factor`. The plot shows `approx_mode=fast`, `normal`, and `accurate` as separate curves. 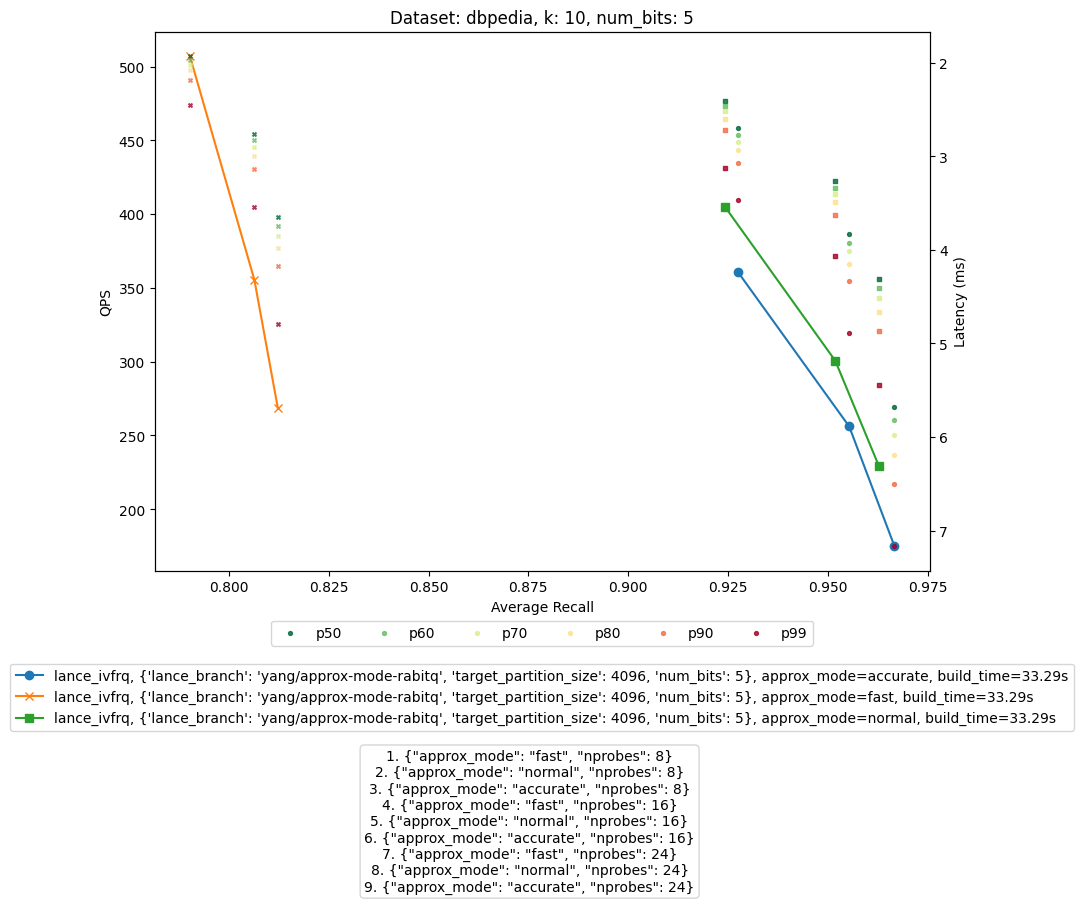 ## Breaking Change BREAKING CHANGE: The ANN protobuf schema now includes `VectorApproxMode approx_mode` on vector query serialization. Consumers that regenerate or explicitly match Lance's serialized ANN query proto should update to the new schema. ## Validation - `cargo fmt --all` - `cargo test -p lance-linalg simd::dist_table` - `cargo test -p lance-index vector::bq::storage` - `cargo test -p lance-index vector::storage::tests` - `cargo test -p lance --features substrait test_query_roundtrip` - `cargo test -p lance test_knn_approx_mode_defaults_and_setter` - `cargo check --workspace --tests --benches` - `cd python && make install` - `cd python && uv run pytest python/tests/test_vector_index.py::test_vector_index_with_approx_mode python/tests/test_vector_index.py::test_vector_index_invalid_approx_mode` - `cd python && uv run pytest python/tests/test_vector_index.py::test_create_ivf_rq_multi_bit_searches_l2_and_cosine` - `git diff --check`
| Commit: | de176bd | |
|---|---|---|
| Author: | Beinan | |
| Committer: | GitHub | |
feat(index): implement FM-Index scalar index for exact substring search (#7026) ## Motivation Enable exact substring search at scale for AI pretraining data decontamination — detecting benchmark contamination in trillion-row text corpora, following the [Infini-gram Mini paper](https://arxiv.org/abs/2506.12229). ## Summary - Implement FM-Index following the Infini-gram Mini paper architecture for exact substring search - Huffman-shaped wavelet tree for entropy-compressed BWT rank queries (~0.26N bytes) - Sampled suffix array (D=32) with LF-mapping locate for document resolution (~0.25N bytes) - Partitioned index (10K docs/partition) with blocked storage (32KB blocks) and lazy loading - Wire up `IndexType::FMIndex` in Lance's `create_index` and query paths (`contains()` filter) - Index size ~0.95x of text (paper claims 0.44x; gap is Lance row overhead per block) ## Benchmark (100K gitlake source code files, 1.59 GB text) | Metric | FM-Index | N-Gram | |--------|----------|--------| | Index size | 1,513 MB (0.95x) | 84 MB (0.05x) | | Build time | 132s | 9s | | Short queries (e.g. `fn `) | 9034ms/q | 448ms/q | | Medium queries (e.g. `fn main()`) | **29ms/q** | 480ms/q | | Long queries (~80 chars) | **34ms/q** | 206ms/q | FM-Index is 17x faster than N-Gram on medium queries and returns exact results (N-Gram returns approximate candidates needing recheck). N-Gram cannot find queries shorter than 3 characters (e.g. `fn ` returns 0). ## Test plan - [x] 9 unit tests covering search, locate, wavelet access, serialization, multi-document - [x] End-to-end benchmark through Lance dataset API (`dataset.create_index`, `dataset.count_rows(filter)`) - [x] Verified correct match counts against full-scan baseline on real source code 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Beinan Wang <beinanwang@microsoft.com>
| Commit: | 6ddd7e2 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
feat: implement vector index details (#6099) Cache vector index configuration within the index metadata, such as the distance type and build parameters. Previously, to determine things like the distance type or index type of a vector index, the index file itself had to be opened. This PR stores that information in `VectorIndexDetails` within the manifest's `index_details` field, which is fetched and cached eagerly when loading the manifest. Old indexes have this field left blank. When blank, the details are extracted from the index files and cached. This migration happens on the first write with a new library version. ## What's stored in VectorIndexDetails **Core build parameters** (typed fields — required for any runtime to build the index): - `metric_type` - `target_partition_size` (IVF) - `hnsw_index_config` — `max_connections`, `construction_ef`, `max_level` (HNSW) - `compression` — PQ/SQ/RQ/flat, including `num_bits`, `num_sub_vectors`, `rotation_type` **Runtime hints** (`map<string, string> runtime_hints`): Optional build preferences that don't affect index structure. Stored so a background rebuild process can reproduce the original configuration. Runtimes that don't recognize a key must silently ignore it. Only non-default values are written. Keys use reverse-DNS namespacing: `lance.*` for core Lance hints, other prefixes for runtime-specific hints (e.g., `lancedb.accelerator` for GPU acceleration in LanceDB Enterprise). Current `lance.*` hints: `lance.ivf.max_iters`, `lance.ivf.sample_rate`, `lance.ivf.shuffle_partition_batches`, `lance.ivf.shuffle_partition_concurrency`, `lance.pq.max_iters`, `lance.pq.sample_rate`, `lance.pq.kmeans_redos`, `lance.sq.sample_rate`, `lance.hnsw.prefetch_distance`, `lance.skip_transpose`. Also adds `apply_runtime_hints()` to read hints back into build params for future rebuild logic. Closes #5963 --------- Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com>
| Commit: | 37eebb4 | |
|---|---|---|
| Author: | Claude | |
perf(encoding): inline mini-block chunk metadata into page layout proto The per-chunk "Words" metadata buffer (a few KB per page) is now also embedded in the MiniBlockLayout protobuf via a new optional field `inline_chunk_meta`. ColumnMetadata is read in a single coalesced I/O at file open, so new readers can populate the chunk metadata from the proto and skip the per-column metadata fetch in MiniBlockScheduler::initialize. When the page has no dictionary and no repetition index, initialize issues zero I/O — addressing the per-column read on the cold search-cache path called out in #4888. The writer continues to emit the metadata buffer at buffer_offsets_and_sizes[0], so older readers (which ignore the unknown proto field) keep decoding correctly. No on-disk format version bump required.
| Commit: | 2f7a96f | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | GitHub | |
feat: builder-style MemWAL initialization API (#6815) ## Summary Replaces the struct-based MemWAL initialization API with a fluent builder on `Dataset`, and persists default `ShardWriter` configuration in the MemWAL index. `Dataset::initialize_mem_wal()` returns an `InitializeMemWalBuilder`: ```rust dataset .initialize_mem_wal() .bucket_sharding("id", 16) .maintained_indexes(["id_btree"]) .writer_config_defaults(ShardWriterConfig::default().with_durable_write(false)) .execute() .await?; ``` - `bucket_sharding(column, num_buckets)`, `unsharded()`, and `identity_sharding(column)` are high-level sharding strategies. They own the `ShardingSpec` construction and validation that callers previously did by hand; `num_shards` is derived from the sharding choice. - `writer_config_defaults(ShardWriterConfig)` records the tunable writer configuration as the persisted defaults — a new `map<string, string> writer_config_defaults` field on the `MemWalIndexDetails` protobuf message — so every writer, across processes and restarts, starts from the same defaults. `add_writer_config_default` records arbitrary extra keys. - The Python `initialize_mem_wal` binding accepts the full builder surface (sharding, maintained indexes, writer-config defaults) and invokes the builder; a new `mem_wal_index_details` binding reads the recorded details back. - Removed: `MemWalConfig`, `MemWalShardConfig`, `initialize_mem_wal_with_shards`. ## Context While reviewing lancedb/lancedb#3396, @jackye1995 noted that per-writer tuning knobs are runtime configuration and should not be persisted as part of the sharding spec. That holds for a writer's *live* `ShardWriterConfig`, which stays non-persisted. This PR records only the *defaults*: without a persisted default, writers would be configured independently and could silently drift apart. @jackye1995 also asked for a builder style so bucket sharding is easy to set, moving the hash-bucket spec logic out of the LanceDB layer into Lance. The builder owns all three sharding strategies (bucket, unsharded, identity), so LanceDB's `set_lsm_write_spec` can call the builder directly instead of hand-building shard specs.
| Commit: | 53b8556 | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | GitHub | |
refactor: rename ShardSpec to ShardingSpec (#6813) ## Summary Renames the `ShardSpec` / `ShardField` types — and the `shard_spec` / `shard_specs` identifiers and the corresponding protobuf messages — to `ShardingSpec` / `ShardingField` for naming consistency. The protobuf message names change and the `shard_specs` field is renamed to `sharding_specs`; all field numbers and tags are unchanged, so the change is wire-compatible.
| Commit: | 1f1af34 | |
|---|---|---|
| Author: | Dan Rammer | |
| Committer: | GitHub | |
fix(mem_wal): stop WAL replay from re-loading already-compacted entries (#6767) ## Summary After a writer flushed a memtable to L0 and an external compactor merged that generation into the base table — legitimately draining `flushed_generations` to empty — a subsequent restart re-replayed the original WAL entries into the new active memtable, duplicating rows on read. Two bugs were interacting: 1. **Disambiguation:** `replay_memtable_from_wal` distinguished "fresh shard" from "flushed and compacted" via `flushed_generations.is_empty()`. That works in a closed-world deployment but breaks the moment an external compactor enters the picture — and the compactor is the *intended* consumer that drains that vector, so the signal is structurally broken under OSS-WAL. 2. **Cursor never advanced:** `MemTableFlusher::flush` read `covered_wal_entry_position` from `memtable.last_flushed_wal_entry_position()`, but that field is only set by the `mark_wal_flushed` test helper. In production it stayed at 0, so `replay_after_wal_entry_position` never advanced past 0. Under 0-based WAL positions this masked bug #1 — both "fresh" and "post-flush-of-0" produced cursor=0. ## Fix - **WAL positions are now 1-based** (`FIRST_WAL_ENTRY_POSITION = 1`). A cursor of `0` unambiguously means "no flush has stamped this shard," so replay collapses to `cursor.saturating_add(1)` without consulting `flushed_generations`. - **`WalFlushHandler::handle`** writes the just-appended position back into `state.last_flushed_wal_entry_position` under the state lock before signalling the completion cell. - **`MemTableFlusher::flush` / `flush_with_indexes`** now take an explicit `covered_wal_entry_position` arg. The production caller derives it per-memtable from the `WalFlushResult` carried in the completion cell — authoritative under concurrent flushes — falling back to `memtable.frozen_at_wal_entry_position()` when freeze did not trigger a flush. - **State seed at open** uses the post-replay WAL tip, not `manifest.wal_entry_position_last_seen` (the latter is bumped on every tailer read and can sit above any flushed generation). - Proto field docs on `ShardManifest.replay_after_wal_entry_position` / `wal_entry_position_last_seen` updated to spell out the 1-based convention and what default-0 means. ## Test plan - [x] Added `test_memtable_replay_skips_entries_after_external_compaction` in `rust/lance/src/dataset/mem_wal/write.rs`: open writer, put rows, close (flush), simulate the compactor by directly committing a manifest with empty `flushed_generations`, reopen, assert the memtable is empty. Fails on the pre-fix code; passes now. - [x] `cargo test -p lance --lib dataset::mem_wal` — 236/236 pass - [x] `cargo test -p lance --lib` — 1600/1600 pass - [x] `cargo test -p lance-index --lib` — 302/302 pass - [x] `cargo clippy --all --tests --benches -- -D warnings` — clean - [x] `cargo fmt --all -- --check` — clean ## Compatibility WAL position numbering changes from 0-based to 1-based. Existing on-disk manifests / WAL files written by the prior `oss-wal-multiplex` code are not migrated — coordinated with downstream consumers (sophon) to start fresh. 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
| Commit: | b33058a | |
|---|---|---|
| Author: | Beinan | |
| Committer: | GitHub | |
feat: add unenforced_clustering_key to format spec (#6552) ## Summary - Add `unenforced_clustering_key` metadata to the Lance schema format, mirroring the existing `unenforced_primary_key` pattern - Clustering keys hint at the physical ordering of data within a table, enabling query engine optimizations such as storage-partitioned joins (SPJ) - Unlike primary keys, clustering key fields may be nullable Changes across all layers: - **Protobuf**: `unenforced_clustering_key` (bool) + `unenforced_clustering_key_position` (uint32) fields 14-15 - **Rust core**: field struct, constants, Arrow metadata parsing, schema method - **Protobuf serialization**: round-trip support with backward compat - **Java JNI + LanceField**: constructor args and getters - **Python bindings + type stubs**: `is_unenforced_clustering_key()` / `unenforced_clustering_key_position()` - **Format docs**: clustering key metadata section ## Motivation This was discussed in the lance-spark SPJ PR (lance-format/lance-spark#445). Rather than using custom table properties, embedding clustering key info in the schema metadata follows the established pattern and avoids migration issues. ## Test plan - [x] `cargo check -p lance-core -p lance-file` passes - [x] `cargo test -p lance-core -p lance-file` passes (all tests including existing primary key tests) - [x] `cargo clippy -p lance-core -p lance-file --tests -- -D warnings` clean 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | 43c3780 | |
|---|---|---|
| Author: | Jerry He | |
| Committer: | GitHub | |
fix: propagate update_columns offsets and partial last_updated for RewriteColumns (#6650) ## Summary * Fixes https://github.com/lance-format/lance/issues/6505 * `FileFragment::update_columns` returns `Result<(Fragment, Vec<u32>)>` (unchanged public shape). `update_columns_with_offsets` returns `FragmentUpdateColumnsResult` (fragment, `fields_modified`, `matched_offsets: RoaringBitmap`) for callers that need physical row indices for stable row-id metadata. * `HashJoiner::matched_join_rows` — boolean mask for hash hits; used by `update_columns_with_offsets` and covered by `test_matched_join_rows`. * `Operation::Update`: optional `updated_fragment_offsets: Option<UpdatedFragmentOffsets>` where `UpdatedFragmentOffsets` wraps `HashMap<u64, RoaringBitmap>` (newtype with `Default`, `PartialEq`, manual `DeepSizeOf`). `None` means the caller did not supply offsets. * Proto (`transaction.proto`): backward-compatible `map<uint64, UInt32List> updated_fragment_offsets = 9` on `Update`; serde round-trip preserves semantics. * `build_manifest`: when stable row IDs are enabled, `update_mode == RewriteColumns`, and `Some(UpdatedFragmentOffsets(..))` includes a non-empty bitmap for a fragment, calls `refresh_row_latest_update_meta_for_partial_frag_rewrite_cols` for those offsets only — unmatched rows and untouched fragments are left unchanged. * JNI / Java: `FragmentUpdateResult` includes matched row offsets; the 2-arg constructor `(FragmentMetadata, long[])` delegates to the 3-arg form with an empty offset array for compatibility. JNI uses `update_columns_with_offsets`. * Python: `update_columns` binding correctly destructures the `(Fragment, Vec<u32>)` tuple. ## Root cause For `Operation::Update` with `RewriteColumns`, commits could advance the dataset version without advancing `_row_last_updated_at_version` for the rows that were actually rewritten. `update_columns` did not report which physical offsets matched, and `build_manifest` had no per-fragment offset map to drive the partial refresh. Without that information the transaction layer cannot distinguish which rows changed, so the version metadata is not updated. ## Implementation notes * `RoaringBitmap` iteration is ascending and duplicate-free; redundant `sort` / `dedup` when building proto lists or offset vectors from bitmaps were removed. * Call sites that do not populate offsets use `updated_fragment_offsets: None`. ## Why the protobuf field exists lance-spark passes `Transaction` through JNI as a protobuf blob: Java builds a `Transaction` proto, Rust deserializes it and runs `build_manifest`. Without `updated_fragment_offsets` on the wire, the decoded `Operation::Update` would always have `updated_fragment_offsets: None` even when matched offsets were computed on the JVM side, and the partial refresh in `build_manifest` would silently do nothing. ## Test plan * `cargo test -p lance test_matched_join_rows` — `HashJoiner::matched_join_rows`. * `cargo test -p lance test_build_manifest_partial_last_updated_rewrite_columns_stable_row_ids` — `Dataset::commit` -> `build_manifest`: two fragments, partial `update_columns_with_offsets`, `Operation::Update` with `RewriteColumns` and an offset map; asserts matched vs unmatched vs untouched row version metadata. * `cargo test -p lance test_fragment_update` — fragment path with `Operation::Update` and offsets. * `cargo test -p lance --tests` (or at least `cargo check -p lance --tests`) and `cargo check --manifest-path java/lance-jni/Cargo.toml`. The `pylance` crate is excluded from the root workspace; validate Python bindings in the usual `maturin` / CI flow if you touch `python/`. ## Compatibility * Rust: `update_columns` signature unchanged; `update_columns_with_offsets` is additive. * Java: 2-arg `FragmentUpdateResult` constructor preserved. * Proto: field 9; older clients ignore unknown fields. --------- Co-authored-by: Jing chen He <jingh@adobe.com>
| Commit: | db02fc9 | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | GitHub | |
feat: add write ahead log appender and tailer primitives (#6669) ## Summary Surface a generic read/write surface for MemWAL shards so callers can drive a shard directly without going through the existing flusher. - **Shard self-description.** `ShardManifest` now records the `(shard_spec_id, field_id -> bytes)` assignment that produced the shard, so a manifest found on disk can be mapped back to a shard spec without consulting the inline index. Proto adds `ShardFieldEntry`; manifest carries `shard_field_values: HashMap<String, Vec<u8>>`. - **Idempotent shard initialization.** `ShardManifestStore::initialize_shard()` writes manifest v1 at writer epoch 0 and treats `AlreadyExists` as success when the existing manifest matches. - **Generic WAL primitives.** - `WalAppender::open()` claims a writer epoch via the manifest store; `append(batches)` serializes Arrow IPC and writes with put-if-not-exists, retrying on conflict and fencing on PUT failure. - `WalTailer::read_entry`, `next_position`, `first_position` use `wal_entry_position_last_seen` as a probe hint with a listing fallback. `WalReadEntry` includes the `writer_epoch` recorded in the entry so callers can fence-check on replay. - **Index discovery helpers.** New `Dataset` methods `mem_wal_index_details()` and `list_mem_wal_latest_shard_ids()` (object-storage directory listing). The inline shard snapshot is positioned as a stale read-optimization rather than the source of truth; `docs/src/format/table/mem_wal.md` is updated to match. ## Tests Added unit tests for: - `ShardManifestStore::initialize_shard` happy path, idempotent on match, rejects mismatched conflict. - `WalAppender` / `WalTailer` round-trip including `writer_epoch` propagation; position increment. - Writer-epoch fencing: a stale appender hits the conflict path on append and surfaces the fence error. - Input validation: empty batch list and zero-row batches are rejected. - `WalTailer::with_cursor_updates(true)` updates `wal_entry_position_last_seen` asynchronously, and `next_position()` still resolves correctly. - `mem_wal_path()` helper. cc @jackye1995 for review.
| Commit: | 27b1c2b | |
|---|---|---|
| Author: | BubbleCal | |
| Committer: | GitHub | |
feat(vector): add partition search parallelism (#6475) ## Feature This PR adds query-time `query_parallelism` for vector search partition execution and wires it through Rust, Python, and Java. Callers can control how many IVF partitions a single query may search concurrently: - `0`: auto policy. The current implementation maps auto to the single-worker sequential path. - `1`: single-worker sequential partition search. - `-1`: use the CPU pool size. - `>= 2`: partition-parallel search, clamped to the CPU pool size. The default is `0`, which currently preserves the optimized sequential execution path. ## Performance Improvement The performance issue is per-query worker fan-out. With many concurrent queries, spawning a CPU task for every partition of every query increases contention on the CPU worker pool and lengthens queueing time. This is especially visible for fixed-`nprobes` IVF workloads where every query searches the same number of partitions. This PR improves that path by making query partition scheduling configurable while keeping the optimized sequential model as the default auto behavior. Sequential fixed-`nprobes` search prepares partitions asynchronously, then searches prepared partitions on one CPU worker using a query-level global top-k heap. Parallel execution remains available for workloads that benefit from intra-query partition parallelism. ## Implementation - Rust, Python, and Java expose `query_parallelism` on vector search APIs. - `ANNIvfSubIndexExec` converts the configured value into an effective partition concurrency. - Effective partition concurrency is clamped to the CPU pool size. - IVF v2 splits partition search into async prepare and sync execute phases. - Sequential fixed-`nprobes` search uses a query-level global top-k heap. - Sequential late-search keeps the existing per-partition output shape so early-stop behavior is preserved. - Parallel execution uses direct per-partition search tasks, matching the original execution model. - IVF_RQ/Flat sub-index search reuses caller-owned scratch buffers for RQ distance-table quantization and top-k accumulation to reduce allocation overhead. ## Developer Impact - Rust callers can call `Scanner::query_parallelism(...)`. - Python callers can pass `query_parallelism` in vector search APIs. - Java callers can use `Query.Builder#setQueryParallelism(...)`. - `parallel_mode` / `ParallelMode` have been replaced by the concurrency-based API. ## Benchmark GCP VM benchmark using the same index for all modes. All rows had matching result checksums. Configuration: `gist / IVF_RQ / target_partition_size=8192 / k=100 / nprobes=20 / columns=[] / prewarm / max_queries=1000`. Percentages are relative to `main`. | Threads | Mode | Avg | P50 | P90 | P95 | P99 | QPS | |---:|---|---:|---:|---:|---:|---:|---:| | 8 | main | 4.98 ms | 4.92 ms | 6.28 ms | 6.86 ms | 7.56 ms | 1584.6 | | 8 | sequential | 4.27 ms (-14.2%) | 4.21 ms (-14.5%) | 5.03 ms (-19.9%) | 5.27 ms (-23.1%) | 5.97 ms (-21.0%) | 1838.9 (+16.1%) | | 8 | parallel | 5.02 ms (+0.7%) | 4.97 ms (+0.9%) | 6.27 ms (-0.2%) | 6.60 ms (-3.7%) | 7.36 ms (-2.7%) | 1575.4 (-0.6%) | | 16 | main | 9.95 ms | 9.74 ms | 13.12 ms | 14.11 ms | 16.83 ms | 1583.1 | | 16 | sequential | 8.09 ms (-18.6%) | 7.98 ms (-18.0%) | 9.84 ms (-25.0%) | 10.47 ms (-25.8%) | 11.67 ms (-30.6%) | 1936.8 (+22.3%) | | 16 | parallel | 9.95 ms (+0.0%) | 9.68 ms (-0.6%) | 13.37 ms (+1.9%) | 14.42 ms (+2.2%) | 16.83 ms (+0.0%) | 1583.6 (+0.0%) | | 32 | main | 18.68 ms | 18.16 ms | 26.66 ms | 28.77 ms | 33.12 ms | 1652.7 | | 32 | sequential | 15.50 ms (-17.0%) | 15.15 ms (-16.6%) | 20.57 ms (-22.9%) | 22.16 ms (-23.0%) | 25.32 ms (-23.6%) | 2000.6 (+21.1%) | | 32 | parallel | 19.13 ms (+2.4%) | 18.58 ms (+2.3%) | 26.49 ms (-0.6%) | 29.12 ms (+1.2%) | 33.92 ms (+2.4%) | 1625.9 (-1.6%) | | 64 | main | 33.98 ms | 33.01 ms | 49.65 ms | 53.87 ms | 63.58 ms | 1718.4 | | 64 | sequential | 29.95 ms (-11.8%) | 29.67 ms (-10.1%) | 42.44 ms (-14.5%) | 46.81 ms (-13.1%) | 54.42 ms (-14.4%) | 1949.4 (+13.4%) | | 64 | parallel | 35.17 ms (+3.5%) | 34.37 ms (+4.1%) | 50.70 ms (+2.1%) | 55.04 ms (+2.2%) | 69.09 ms (+8.7%) | 1650.7 (-3.9%) | | 128 | main | 38.73 ms | 36.07 ms | 68.28 ms | 76.78 ms | 96.81 ms | 1663.3 | | 128 | sequential | 37.48 ms (-3.2%) | 35.90 ms (-0.5%) | 65.26 ms (-4.4%) | 71.82 ms (-6.5%) | 87.48 ms (-9.6%) | 1915.3 (+15.2%) | | 128 | parallel | 41.29 ms (+6.6%) | 39.38 ms (+9.2%) | 71.68 ms (+5.0%) | 80.70 ms (+5.1%) | 96.20 ms (-0.6%) | 1577.2 (-5.2%) | ## Validation - `cargo fmt --all --check` - `cargo check -p lance --tests` - `cd python && cargo check` - `cd java && cargo check --manifest-path ./lance-jni/Cargo.toml` - `uv run --with maturin maturin develop` - `uv run pytest python/tests/test_vector_index.py::test_vector_index_with_query_parallelism python/tests/test_vector_index.py::test_vector_index_invalid_query_parallelism` - Python ruff check / format check for touched Python files
| Commit: | 2939443 | |
|---|---|---|
| Author: | LuQQiu | |
| Committer: | GitHub | |
feat: add prefilter_type to ANNIvfSubIndexExecProto (#6613) ## Summary - Add `PreFilterType` enum (`None`, `FilteredRowIds`, `ScalarIndexQuery`) to `ANNIvfSubIndexExecProto` in `ann.proto` - Encode sets `prefilter_type` based on the exec's `PreFilterSource` variant - Decode uses `prefilter_type` from the proto to reconstruct the correct `PreFilterSource` variant, replacing the schema-sniffing heuristic used by downstream codecs - Errors on inconsistent state: prefilter type set but no child plan provided, or child plan provided but type is `None` This enables downstream codecs (e.g. sophon's `LancePhysicalExtensionCodec`) to correctly reconstruct `PreFilterSource` without guessing from the child plan's schema. ## Test plan - [x] `test_ann_ivf_sub_index_proto_roundtrip` — existing None prefilter roundtrip (updated to new API) - [x] `test_sub_index_proto_roundtrip_filtered_row_ids` — FilteredRowIds encode/decode - [x] `test_sub_index_proto_roundtrip_scalar_index_query` — ScalarIndexQuery encode/decode - [x] `test_sub_index_proto_error_type_none_but_child_provided` — errors on mismatch - [x] `test_sub_index_proto_error_type_set_but_no_child` — errors on mismatch 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | b895d57 | |
|---|---|---|
| Author: | LuQQiu | |
| Committer: | GitHub | |
feat: add ANNIvfPartitionExecProto (#6612)
| Commit: | 65c8a98 | |
|---|---|---|
| Author: | LuQQiu | |
| Committer: | GitHub | |
feat: add ANN proto codecs and extract table_identifier module (#6503) Add protobuf encode/decode for `ANNIvfSubIndexExec` --------- Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | e619ad7 | |
|---|---|---|
| Author: | majin1102 | |
feat: add generated row id ranges
| Commit: | bd555c2 | |
|---|---|---|
| Author: | majin1102 | |
refactor: narrow reserved row id proto scope
| Commit: | 5a4eff3 | |
|---|---|---|
| Author: | majin1102 | |
docs: clarify reserved row id append semantics
| Commit: | e248c70 | |
|---|---|---|
| Author: | majin1102 | |
refactor: derive reserved row ids from transactions
| Commit: | 6b4739d | |
|---|---|---|
| Author: | majin1102 | |
feat: reserve stable row ids for append transactions
| Commit: | 408a951 | |
|---|---|---|
| Author: | Dan Rammer | |
| Committer: | GitHub | |
refactor: rename "region" to "shard" in mem_wal implementation (#6367) Avoid confusion with object store regions (e.g., AWS regions) which are unrelated to the MemWAL concept of a unique writer/reader instance. Closes https://github.com/lance-format/lance/issues/6355 Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | bf8b3b2 | |
|---|---|---|
| Author: | Lu Qiu | |
refactor: align proto field names with Rust struct fields, serialize full IndexMetadata - Rename `distance_type` to `metric_type` in VectorQueryProto (matches Query.metric_type) - Replace `index_name` + `segment_uuids` with `repeated bytes indices` in ANNIvfSubIndexExecProto, serializing full IndexMetadata via prost-encoded bytes from lance.table package (avoids lossy UUID-only serialization and removes load_indices_by_name roundtrip on deserialization) - Fix unused variable warning in make_indexed_dataset test helper - Move test imports to top of test module - Remove stale doc comment in table_identifier.rs - Strengthen sub-index roundtrip test to verify IndexMetadata fields Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | 21a24cb | |
|---|---|---|
| Author: | Lu Qiu | |
refactor: extract table_identifier module, add sub index roundtrip test - Move table_identifier_from_dataset, table_identifier_from_dataset_with_manifest, and open_dataset_from_table_identifier into a shared table_identifier module so both filtered_read_proto and ann_ivf_proto use the same code - Re-export from filtered_read_proto for backwards compatibility - Remove PE-specific comments from ann_ivf.proto (open source doesn't need to know PE) - Add test_ann_ivf_sub_index_proto_roundtrip with a real IVF index Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | 8c9fc8a | |
|---|---|---|
| Author: | Lu Qiu | |
feat: add proto serialization for ANNIvfPartitionExec and ANNIvfSubIndexExec Add protobuf definitions and encode/decode functions for distributed execution of ANN IVF plan nodes, following the FilteredReadExec pattern. Key design choices: - VectorQueryProto round-trips ALL Query fields using Arrow IPC for the key array (supports Float16/Float32/Float64/UInt8, not just Float32) - DistanceType uses Display/TryFrom<&str> instead of manual match - from_proto functions take Option<Arc<Dataset>> so callers can pass from cache or let it open from storage (same as FilteredReadExec) - ANNIvfSubIndexExec from_proto takes input + prefilter_source as params — codec on the caller side handles child extraction Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
| Commit: | 023b14b | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
feat: add file list with sizes to IndexMetadata (#5497) Start storing the size of index files in the manifest file. Now you get the byte size of an index in `describe_indices()`: ```python >>> ds.describe_indices() [IndexDescription(name='x_idx', ..., total_size_bytes=1475), IndexDescription(name='y_idx', ..., total_size_bytes=2772)] ``` Because we can now skip the `HEAD` request to get file size, this reduces read IO requests for cold queries: | Case | Before | After | |------|-------:|------:| | Cold BTree search | 5 | 3 | | Warm BTree search | 1 | 1 | | Cold FTS search | 10 | 5 | | Warm FTS search | 1 | 1 | (Cold queries now do 1 IOP per index file, plus 1 for taking results. BTree has two files, while FTS has 4 files, so that's why it's 3 and 5 IOPs respectively.) Migration is handled on write: when we commit, we check for any indices missing the files field and will add them as needed. Closes https://github.com/lance-format/lance/issues/5226 --------- Co-authored-by: Claude Opus 4.5 <noreply@anthropic.com>
| Commit: | 5abeffa | |
|---|---|---|
| Author: | Yingjian Wu | |
| Committer: | Will Jones | |
feat: compress complex all null (#4990) In order to compress complex all null, we need to add additional parameters in the proto so we know what compression are used for definition level and repetition level and the number of values accordingly. resolve https://github.com/lancedb/lance/issues/4885 --------- Co-authored-by: stevie9868 <yingjianwu2@email.com> Co-authored-by: Xuanwo <github@xuanwo.io>
| Commit: | 3ef07fe | |
|---|---|---|
| Author: | Yingjian Wu | |
| Committer: | GitHub | |
feat: compress complex all null (#4990) In order to compress complex all null, we need to add additional parameters in the proto so we know what compression are used for definition level and repetition level and the number of values accordingly. resolve https://github.com/lancedb/lance/issues/4885 --------- Co-authored-by: stevie9868 <yingjianwu2@email.com> Co-authored-by: Xuanwo <github@xuanwo.io>
| Commit: | 540e973 | |
|---|---|---|
| Author: | LuQQiu | |
| Committer: | GitHub | |
feat: serialize storage options in table identifier proto (#5973) add storage options in table identifier proto to allow pass in storage credentials or information. Make `dataset` parameter optional in `filtered_read_exec_from_proto`, falls back to opening from the proto's table identifier
| Commit: | 441bd9e | |
|---|---|---|
| Author: | LuQQiu | |
| Committer: | GitHub | |
feat: add proto serialization for FilteredReadExec (#5954) Add protobuf definitions and to_proto/from_proto conversion helpers so a PhysicalExtensionCodec can serialize FilteredReadExec plans for distributed execution (planner → executor). Proto types (TableIdentifier, FilteredReadOptionsProto, FilteredReadPlanProto) live in lance-datafusion as data containers. Conversion logic lives in lance::io::exec::filtered_read_proto because it needs access to FilteredReadExec and Dataset. Filter expressions use existing Substrait serialization; RowAddrTreeMap uses its built-in binary format. Arrow types using existing Arrow IPC serialization
| Commit: | 204d9b5 | |
|---|---|---|
| Author: | BubbleCal | |
precompute rotated centroids Signed-off-by: BubbleCal <bubble-cal@outlook.com>
| Commit: | d7685f6 | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | GitHub | |
feat: evolute all_null_layout to constant layout (#5641) This PR will evolute all_null_layout to constant layout as mentioned in https://github.com/lance-format/lance/discussions/5631 The logic for checking validity and constant values is a bit clumsy, but I haven't found a better approach yet. --- **Parts of this PR were drafted with assistance from Codex (with `gpt-5.2`) and fully reviewed and edited by me. I take full responsibility for all changes.**
| Commit: | 62f3a06 | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | Jack Ye | |
feat: introduce MemWAL regional writer and MemTable reader
| Commit: | cb644f2 | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | GitHub | |
feat: use independent region manifest for MemWAL (#5689) Based on discussion with @jackye1995 past few days, update the current MemWAL structure to introduce region specific manifest for independent update so that it can more efficiently run updates in streaming engines like Flink. This mostly comes from draft from @jackye1995, but separate out the MemWAL index part first with some my custom edits. --------- Co-authored-by: Claude Opus 4.5 <noreply@anthropic.com> Co-authored-by: Jack Ye <yezhaoqin@gmail.com>
| Commit: | d1ec03c | |
|---|---|---|
| Author: | Heng Ge | |
| Committer: | GitHub | |
feat: add order to primary key (#5683) This PR adds ordering to primary key so that it can be used for btree index. This is a part of the work to make the MemTable proposal work after discussion with @jackye1995, and for my use case the primary key has to be multiple. --------- Co-authored-by: Claude Opus 4.5 <noreply@anthropic.com>
| Commit: | 8dbcfd2 | |
|---|---|---|
| Author: | Jack Ye | |
| Committer: | GitHub | |
feat: merge-insert with primary key dedupe (#5633) Based on https://github.com/lance-format/lance/pull/4787 Co-authored-by: vinoyang <vinoyang@apache.org>
| Commit: | e451867 | |
|---|---|---|
| Author: | Xuanwo | |
feat: add classic alp encoding support
| Commit: | 7f4d8f6 | |
|---|---|---|
| Author: | Xuanwo | |
feat: Implement alp encoding
| Commit: | d7504c2 | |
|---|---|---|
| Author: | Xin Sun | |
| Committer: | GitHub | |
feat: add RTree index spec in table format (#5360) This PR proposes adding the R-Tree index specification to the Lance table format. For implementation details please see #5034 Feel free to leave comments or share feedback
| Commit: | 3c37b4b | |
|---|---|---|
| Author: | ForwardXu | |
| Committer: | GitHub | |
docs: fix duplicate words in comments and error messages (#5548) Fixed 7 instances of duplicate words: - 'to to' → 'to' (3 occurrences) - 'the the' → 'the' (4 occurrences) This is a documentation/comment cleanup with no functional changes.
| Commit: | 838534b | |
|---|---|---|
| Author: | Yue | |
| Committer: | GitHub | |
feat: add support for large minichunk size (u32) in format v2.2 (#4959)
| Commit: | 526a9ba | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
ci: resolve rustdoc warnings and add CI check (#5428) ## Summary - Fix documentation issues that trigger warnings when building with `RUSTDOCFLAGS="-D warnings"` - Add a CI job that runs `cargo doc` with warnings treated as errors to prevent future regressions ### Documentation fixes include: - Escape generic types in doc comments (e.g., `Vec<T>`, `List<u8>`) - Fix broken intra-doc links to private/non-existent items - Wrap bare URLs in angle brackets - Fix unclosed HTML tags from generic type syntax - Change invalid code block markers in proto files 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.5 <noreply@anthropic.com>
| Commit: | 1024091 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
feat: add describe_indices function (#5221) The list_indices function relies on APIs from the index objects themselves. This means we need to load the indices to populate the information. In addition, the python function uses the index statistics which can be slow. Rather than modify the existing method (which may introduce a breaking change) this creates a new method `describe_indices`. This method only uses information available in the dataset manifest. This ensures that minimal I/O will be required (loading the manifest if it hasn't been loaded) and the call shouldn't be slow.
| Commit: | 40409d6 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
chore: move deprecated fields to bottom in Field msg (#5211) In the `Field` message, there are several fields that are deprecated or no longer apply in V2 file format. I'm moving them to the bottom of the message so they aren't distracting.
| Commit: | 46a249a | |
|---|---|---|
| Author: | nathan.ma | |
| Committer: | GitHub | |
feat: provide inline_transaction model for IO optimizing (#4774) Hi, @wjones127, @jackye1995 , I'm working on issue #4308 #3487 In this PR I wanna proposing the inline_transaction model for IO optimizing. The motivation includes: 1. Get transaction summary without transaction file IO 2. Optimize commit by reducing transaction file IO
| Commit: | 79d2a35 | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | GitHub | |
refactor: remove not used storage class and blob dataset (#5131) This PR removes unused storage class and blob dataset to make our logic cleaner and easier to follow. That’s especially important as we work on support for blob v2 now. This PR includes breaking changes at the API level, but since we never used a blob dataset before, it won’t break users’ existing datasets. --- **This PR was primarily authored with Codex using GPT-5-Codex and then hand-reviewed by me. I AM responsible for every change made in this PR. I aimed to keep it aligned with our goals, though I may have missed minor issues. Please flag anything that feels off, I'll fix it quickly.** --------- Signed-off-by: Xuanwo <github@xuanwo.io>
The documentation is generated from this commit.
| Commit: | 4cfb99b | |
|---|---|---|
| Author: | Jack Ye | |
| Committer: | GitHub | |
fix: forward incompatibility of prerelease in writer version (#5116) WIth previous CI change, we now use the actual prerelease version as writer version. However, old version cannot parse such version string and cause panic. This PR makes sure that the version in WriterVersion is always just major.minor.patch. Any prerelease and build metadata are stored separately and not visible to old clients.
| Commit: | 40346c2 | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | GitHub | |
feat: add VariablePackedStruct defination (#4950) Part of https://github.com/lancedb/lance/issues/2862 This PR will add VariablePackedStruct defination in lance first. **This PR was primarily authored with Codex using GPT-5-Codex and then hand-reviewed by me. I AM responsible for every change made in this PR. I aimed to keep it aligned with our goals, though I may have missed minor issues. Please flag anything that feels off, I'll fix it quickly.** --------- Signed-off-by: Xuanwo <github@xuanwo.io> Co-authored-by: Weston Pace <weston.pace@gmail.com>
| Commit: | f88346c | |
|---|---|---|
| Author: | Xuanwo | |
| Committer: | GitHub | |
Merge branch 'main' into packed-strut-with-utf8
| Commit: | d60ed51 | |
|---|---|---|
| Author: | Xuanwo | |
Refactor Signed-off-by: Xuanwo <github@xuanwo.io>
| Commit: | 85d44b6 | |
|---|---|---|
| Author: | vinoyang | |
| Committer: | GitHub | |
feat: support tracking newly inserted and updated rows between versions (#4741) Co-authored-by: Jack Ye <yezhaoqin@gmail.com>
| Commit: | 1b09706 | |
|---|---|---|
| Author: | Jay Narale | |
| Committer: | GitHub | |
feat: implement add_bases api to add bases to lance dataset (#4945) Follow up of [commit](https://github.com/lancedb/lance/commit/dba1e0f2c70c8b41dcf7dc29db37422022c861d9#diff-e053fd3f17169afa9b8ec27bc109b55a1fbae5442d6d0818fc15baef76286b6f). Sample API ``` dataset.add_bases([ DatasetBasePath(test2_base, name="test2_base"), DatasetBasePath(test3_base, name="test3_base"), ]) ```
| Commit: | e49f7af | |
|---|---|---|
| Author: | Xuanwo | |
feat: add VariablePackedStruct defination Signed-off-by: Xuanwo <github@xuanwo.io>
| Commit: | dba1e0f | |
|---|---|---|
| Author: | Jay Narale | |
| Committer: | GitHub | |
feat: add multi-path support for lance data paths (#4765) Fixes #4702 Supports writing to multi bases for lance datasets. Co-authored-by: Jack Ye <yezhaoqin@gmail.com>
| Commit: | bb8841b | |
|---|---|---|
| Author: | Wyatt Alt | |
| Committer: | Wyatt Alt | |
fix: forward compatibility for scalar index protobuf type URLs This backports a forward-compatibility fix to v0.31.2-beta.3, enabling safe reverts from later versions.
| Commit: | d2962ff | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
docs: rework file specification docs (#4619) I had some time on a flight and wrote up some more details on the file spec.
| Commit: | 3cf9103 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
feat: allow reading blob descs in 2.1, fix bugs in FSL decoder when items are nullable (#4840) This also fixes a number of unit tests today that hard-code the version and adds a python utility to get the current stable version as a string (useful for testing to determine the expected value of certain fields)
| Commit: | 8691134 | |
|---|---|---|
| Author: | nathan.ma | |
| Committer: | GitHub | |
feat(rust)!: support branch based on shallow_clone (#4710) After some messy rebases that caused issues, I created this fresh PR for a clean slate @jackye1995 . Design doc: https://github.com/lancedb/lance/discussions/4256#discussioncomment-14304177(completed feature for that part.)
| Commit: | 04a91b2 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
feat: implement blob encoding for 2.1 (#4802) This PR fully adds the blob encoding back into 2.1. The PR is slightly lazy at the moment. For scheduling we simply load the descriptions as part of the search cache in the initialization of the scheduler. In the future we may not want to do that since it could be memory intensive. We should instead spawn a new task to decode the descriptions via indirect I/O. That can be saved for a follow-up however.
| Commit: | f519e82 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
fix: move indexes back to table.proto to avoid forward compat. issues (#4786) This also adds forward compatibility testing for all scalar indexes (not FTS)
| Commit: | f363402 | |
|---|---|---|
| Author: | Will Jones | |
| Committer: | GitHub | |
feat: add table metadata, support incremental updates of all metadata (#4350) BREAKING CHANGE: `Operation::UpdateConfig` and Python and Java bindings of it now have different fields. They are still readable when serialized (and will be automatically translated), but calls to the SDK will need to be adapted. * **Format changes**: * Adds a new field `table_metadata` to store metadata about the dataset. This is separate from schema metadata, as it doesn't get attached to scan results. This is different than `table_config`, as it is meant to be user facing metadata rather than configuration options. * Changes `UpdateConfig` to use a consistent `UpdateMap` entry for all metadata updates. This adds support for incremental changes (upsert) to metadata. * Old fields are kept for backwards compatibility but deprecated. * **Library changes**: * Made consistent APIs for updating all four kinds of metadata: schema, field, table, and config. * All changes backwards compatible, except the `Operation::UpdateConfig` 🤖 Generated with [Claude Code](https://claude.ai/code) --------- Co-authored-by: Claude <noreply@anthropic.com>
| Commit: | a05d78d | |
|---|---|---|
| Author: | vinoyang | |
| Committer: | GitHub | |
feat(rust): support refresh frag bitmap for index after updating when enable stable rowid (#4589) … enable stable rowid
| Commit: | dbe8661 | |
|---|---|---|
| Author: | Haocheng Liu | |
| Committer: | GitHub | |
feat: add bloom filter filter support (#4530) # Summary This PR introduces an inexact index called `BloomFilter` which applies the [split block bloom filter](https://arrow.apache.org/rust/parquet/bloom_filter/index.html) to the desired column. You can find more about this space efficient probabilistic data structure [here](https://en.wikipedia.org/wiki/Bloom_filter). The filter is configurable via environment variable `LANCE_BLOOMFILTER_DEFAULT_NUMBER_OF_ITEMS` and ` LANCE_BLOOMFILTER_DEFAULT_PROBABILITY`. Address #4517 # Changes Made * Add the bloomfilter in Rust * Exposed the bloomfilter to Python # Breaking Changes * None # Test Results * Add thorough tests in Bloomfilter.rs * Add new Python tests in test_scalar_index.py # API Impact * A new filter called `BLOOMFILTER` is introduced to the Python create_scalar_index(...) function --------- Co-authored-by: Weston Pace <weston.pace@gmail.com>
| Commit: | 9d04d29 | |
|---|---|---|
| Author: | Jack Ye | |
| Committer: | GitHub | |
feat!: add MERGED state to MemWAL index (#4673) Fixes #4611 This PR adds a new MERGED state to the MemWAL state machine to better distinguish between data that has been flushed to disk versus data that has been fully merged into the source table. Previously FLUSHED directly means MERGED, which causes too many MemTables accumulated in memory and cannot be dropped until they are sequentially merged. This new state allows flushing MemTables to disk as soon as possible to mitigate memory pressure. BREAKING CHANGE: related APIs `MergeInsertJobBuilder. mark_mem_wal_as_flushed` is renamed to `MergeInsertJobBuilder.mark_mem_wal_as_merged` based on the new definition. --------- Co-authored-by: Claude <noreply@anthropic.com>
| Commit: | 6179196 | |
|---|---|---|
| Author: | Jim Apple | |
| Committer: | GitHub | |
docs: non-optional enum fields in proto3 do not have explicit presence (#4642) It is not possible to read DeletionFile.file_type and get back a value of "unspecified". For better or worse, an absent value will be read as ARROW_ARRAY: https://protobuf.dev/programming-guides/field_presence
| Commit: | 5e63154 | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
feat: add a scalar index for JSON (#4621) Adds a scalar index for JSON columns by creating a scalar index on some sub-field in the JSON data. Any scalar index type can be used as the underlying type. This PR also introduces the ability to configure scalar indexes in a generic way. It might be nice to eventually switch the Inverted index so that it can also be trained in this way (and then we don't need a special "create full text index" method) but that can be left for future work. This PR also modifies the expression parsing slightly to introduce the idea that a query might match a direct column reference _or_ might match a projected column reference. This could be useful in the future for things like indexes on struct fields, list items, image metadata, etc. --------- Signed-off-by: Xuanwo <github@xuanwo.io> Co-authored-by: Xuanwo <github@xuanwo.io>
| Commit: | a40c17a | |
|---|---|---|
| Author: | Weston Pace | |
| Committer: | GitHub | |
refactor: rework scalar index loading, training, and parsing into a plugin trait (#4584) These operations were previously all done via match statements. This made it difficult to create new index types.
| Commit: | e2f08db | |
|---|---|---|
| Author: | nathan.ma | |
| Committer: | GitHub | |
feat!: shallow_clone supports index (#4553) Context: https://github.com/lancedb/lance/pull/4257#issuecomment-3196495952 --------- Co-authored-by: Jack Ye <yezhaoqin@gmail.com>
| Commit: | 746d2dd | |
|---|---|---|
| Author: | nathan.ma | |
| Committer: | GitHub | |
feat!: support shallow_clone in dataset (#4257) This is the prototype of shallow clone. Design document: #4256 I did tests on some real datasets. It's OK to do some basic read and write. We may need some deeper testcases. If there are confusing concepts or details. Please let me know or refer to the document. @jackye1995 cc @wojiaodoubao --------- Co-authored-by: majin.nathan <majin.nathan@bytedance.com>
| Commit: | b3a41fd | |
|---|---|---|
| Author: | Haocheng Liu | |
| Committer: | GitHub | |
feat: add zonemap filter support to Lance at table level (#4244) # Summary This PR introduces an inexact index called `ZoneMap` which breaks the column into fixed-size chunks called zones and stores summary statistics for each zone (min, max, null_count, nan_count, fragment_id). It's very small but only effective if the column is at least approximately in sorted order. The zone size is configurable via environment variable `LANCE_ZONEMAP_DEFAULT_ROWS_PER_ZONE`. Address #4162 and #4360 # Changes Made * Add the zonemap filter in Rust * Exposed the zonemap filter to Python * Make re_map(...) function configurable for all scalar filters * Make the recheck logic configurable on SargableQuery by moving the logic from filter level to SargableQueryParser # Breaking Changes * None # Test Results * Add thorough tests in ZoneMap.rs * Add new Python tests in test_scalar_index.py # API Impact * A new filter called `ZONEMAP` is introduced to the Python create_scalar_index(...) function